
I don’t really remember what the first warning sign was.
The fact that Anu grabbed the bag of chickpea flour from the pantry thinking it was all-purpose?
Or maybe it was the cup she grabbed to measure out the flour?
(And no…I don’t mean measuring cup. It was a cup. One that you would come home after a long day at lab and pour single malt scotch water into.)
Either way, it was at some point in between the two that I started watching with hawk-eye intensity the goings on in my kitchen.

And then when she actually took the glass, filled it with flour, and started tapping it on the side as if to “measure” it….that was when I intervened.
It had become apparent that this pancake-making expedition was going nowhere fast (and by “nowhere” I mean that it was headed straight down the road to inedible), and I just couldn’t bear the thought of bad pancakes being produced in my kitchen.
(And if we’re being honest, I was also a little scared as to what kind of hell would break loose if I did just let her carry on. Images of ruined pans and blaring fire alarms ran through my head.)

My roommate and her boyfriend had sat me down the night before and informed me that the next morning, they were going to be making pancakes. For the first time. Ever. And what did I think they would need?
Of course, their morning coincides with my lunch, so though I kind of hoped that I would miss the entire extravaganza while I was at the gym, part of me knew that we would inevitably end up in the kitchen at the same time. Me, stirring my quinoa chowder, silently from my corner of the stove…them arguing about the interchangeability of baking soda and baking powder from theirs. (Don’t worry…I quickly set them straight.)

Trust me. It was for the best that I was there.
And after explaining to them at least three times that a “teaspoon” was not the same as a spoon that one stirred tea with and doing a flying leap across the kitchen to prevent a metal spatula from adulterating my nonstick pan.
After they were safely tucked away in Anu’s room. Eating. Happily.
I got to dig into my chowder. And maybe it was the fact that by this point, I was hungry enough to eat my own hand…but it was all the comfort I needed after that trying kitchen experience. There are no crazy innovative flavor combinations in here, just tried and true favorites that you can depend on to taste good.

Quinoa Chowder with Sweet Potatoes, Spinach, Feta and Scallions
Serves 4, adapted from Deborah Madison’s Vegetarian Cooking for Everyone
Ingredients
- 3/4 cup quinoa, rinsed well
- 1 tbsp olive oil
- 3 garlic cloves, finely chopped
- 1 jalapeno chile, seeded and finely diced
- 1 tsp ground cumin
- salt and freshly milled pepper
- 1/2 lb sweet potatoes, peeled and cut into 1/4-inch cubes
- 1 bunch scallions, including an inch of greens, thinly sliced into rounds
- 6 cups baby spinach
- 1/4 lb feta cheese, finely diced
- 1/3 cup chopped cilantro
Instructions
- Put the quinoa and 2 quarts of salted water in a pot. Bring to a boil, then lower the heat and simmer for 10 minutes. While it’s cooking, dice the vegetables and cheese. Drain, saving the liquid. Measure the liquid and add water to make 6 cups if needed.
- Heat the oil in a soup pot over medium heat. Add the garlic and chile. Cook for about 30 seconds, giving it a quick stir. Add the cumin, 1 tsp salt, and the potatoes and cook for a few minutes, stirring frequently. Don’t let the garlic brown. Add the quinoa water and half the scallions and simmer until the potatoes are tender, about 15 minutes. Add the quinoa, spinach, and remaining scallions and simmer for 3 minutes more. Turn off the heat and stir in the feta and cilantro. Season with salt and black pepper.







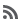


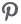







I’ve never had feta in soup, but this combination sounds great together.
I never thought to put quinoa in a chowder but it looks and sounds great!
What a great use of quinoa. This looks like the perfect balance of heart and light.
Mmmm health food at its best!
Well, at the very least she would have created some…interesting…pancakes!
All my healthy favorites in one dish!
Oh if only I had this for dinner tonight. I have been under the weather and this would just make me so happy. So when should I expect it at my door? LOL! Seriously, wonderful combo of textures and flavors!
Yum – healthy comfort food – who knew?
Ok, now I’m kind of freaked out… This is, no joke, exactly what I had been craving but unable to put my finger on. I was Googling “quinoa congee” and not quite coming up with what I had in mind… Because this is it. Holy crap, are you sure you’re not psychic/reading my mind?
This knocks that black bean sauce on Friday night out of the park! Your chowder sounds amazing.
I would have had to leave the city if my roomates were in the kitchen like that…
Maybe you should have let them continue, by accident they may have invented a new super delicious dish, minus a good frypan:)
Oh, this is torture! I’m never coming back here during my lunch break. That looks amazing!!!
?
Camila Faria
your kitchen is one very busy place.
and yeah, i gotta admit, i kind of made an ugly face at your recent comment on my blog about your friend who put coulis on applesauce. for the love! waste.
I was cringing throughout your whole story about the pancakes… It might sound snobby or overly picky, but that’s exactly why I don’t let most other people into my kitchen. >.< I suppose they have to start somewhere... Anyway, this looks delicious!
Awwww… let them eat pancakes. However else are they going to learn? The soup is coming to my kitchen. I have it all and this will soothe me on the next snowy day.
Oh man, what a story! This chowder = perfection.
So how did the pancakes actually turn out? What’s funny is, I can totally see YOU creating some sort of wild amazing pancake out of chickpea flour. Granted, you would be doing it on purpose, not because you don’t know any better. I’ll be waiting for that post…
I’ve never tried quinoa in a soup before!
Hmmm – has delicious and comfort written all over it Joanne. Seriously!!!
They were lucky to have you around to help with the pancakes, and you were lucky to have this comforting soup!
Oh super yum! I have some spinach, cilantro and scallions I need to use up, and it’s fend for yourself night, so I know what I’m making for dinner. I’ll sprinkle the feta on top, so my vegan friend can try this!! This will be perfect for lunches this week!
That looks really good and really hearty. I even have a bag of quinoa that’s just begging to be used. I don’t know what I am waiting for!
So glad you didn’t have to eat your own hand. Yes, the chowder is a much better meal. And how fortunate for your nonstick pan that you were in the kitchen at that exact moment. Not to mention how awful chickpea flour pancakes would have been. Ew.
We do healthy clean eating and this recipe will fit right in!
http://healthycomfort.blogspot.com/
mmmmm…quinoa and sweet potatoes. Fabulous!
Also, you should do food stand up.
Does that exist?
Let’s invent it.
Haha! Wow. My question is–how can they know so little about baking when they have YOU in the apartment, with your extensive stash of culinary knowledge? Or does all the baking and cooking usually just fall to you?
I would love to frame your first photo and put it on my kitchen… gorgeous picture!
I was laughing all the way through the description of your lunch break, and wondering if your room mate reads your blog? Probably not, but she should – a ton of knowledge here, and I bet their pancakes would turn out awesome!
Quinoa in soup-great idea! This soup is making me hungry for lunch. What a great way to pack in so many vegetables and have a tasty meal!
Oh my, haha. That reminds me of Sleeping Beauty where the fairy is trying to bake a cake and uses 3 different cups to measure flour and then folds whole eggs in the shell into the batter, haha. Your soup looks awesome. I really need to make something with quinoa in it, I’ve been majorly craving it lately and this looks delicious.
That is a great idea of using quinoa in soup…perfect with all the veggies and spices…beautiful pictures Joanne!
Hope you have a great week ahead 🙂
Thank goodness you saved the day. I can only imagine how those pancakes would have turned out had you not been there!
I love all of the quinoa recipes I’m seeing lately. I can’t believe it took my so long to try the stuff. This sounds great!
Love all the healthy stuff in this bowl!
I have the hardest time watching other people cook. I try to stay silent and be respectful, but oh my gosh….some people don’t have the first clue.
This is such a pretty soup, Joanne.
ha, what a fiasko 🙂 glad you were there to help out! this looks like such a perfect winter warmer… wishing i had a bowl to look forward to for dinner tonight!
Your soups are always the most gorgeous bowls of comfort!
What a great way to prepare quinoa; I will do this the next time I need a quinoa fix.
LOL! I can totally picture your furtive looks and lip-biting, deep-breath-taking observations of their shenanigans. 🙂 So glad you had this cozy, comforting, savory chowder to turn to in the end. 🙂
This sounds really good! Both nice and tasty and super healthy!
Ha! I’ve been known to go air-borne to save a favorite pan, as well. I love this unusual combination…I can almost taste the salty bites of feta amidst the earthy quinoa and sweet tater! Mmmm…
I have never put quinoa in a soup. It looks so delicious.
Love the vibrant colours and quality ingredients… wholesome eating never tasted so good!
Oh my, this looks so creamy and wonderful. I’d like to try this with regular potatoes instead of sweet potatoes. The combination of spinach and feta is to die for.
What would they have done without your help? Thank goodness you were there. And thank goodness you posted this awesome recipe!
This couldn’t get any better, Joanne. Seriously. I would take a bowl of this over waffles any day. Yum! This is definitely getting pinned.
This looks so delicious and I love spinach in soups and stews!
hehe, sharing a kitchen can be tough! This quinoa chowder looks really good, though, Joanne. I think you are the kitchen winner here. 🙂
YUM!!! You always make the best soups!!!
What an awesome soup! It’s been a while since I’ve done anything with quinoa. This is going on the list.
One of the most delicious and healthy soups I’ve ever seen! All of my favorites in one comforting bowl. Haha funny about your roommate.
Quinoa chowder… that is a brilliant idea. I need to try this!
This comment has been removed by the author.
ohhhh this sounds excellent. and chowder sounds so fancy. love!
I bet the pancakes would have been quite interesting if you wouldn’t have stepped in. The chowder looks lovely, filling, and so delicious.
That story made my night. There’s certainly a careful balance between giving wanted and unwanted advice which I walk carefully with others when they are cooking. I’m intrigued by your chowder. I always think of chowder as thick, rich and pretty unhealthy, so I’m looking forward to trying this!
Quinoa in soup… why didn’t I think of that?? Yet again, a total winter winner!!
I made this tonight! I own the Deborah Madison cookbook it’s from and I think sweet potatoes is the total star of this soup. Well done! It really was easy and delicious. It’s the first thing with quinoa that I’ve liked.
It amazes me that people can get that far in life without knowing how to make pancakes!! This recipe sounds so good. You know how I feel about sweet potatoes – and they are calling my name from this recipe!
That looks lovely and so comfy, Joanne!
Random question: what time DO you get up? I’ll bet my breakfast is your dinner! haha!
Oh sheesh your tales of sharing your kitchen with your roommate made me shudder. Times are tough for me right now and I have been thinking about getting a flatmate in to help pay my mortgage, but in reality I just can’t bear the thought of anyone else in my kitchen.
On the other hand there is absolutely nothing cringe worthy about this chowder – I love everything about it.
Sue xo
quinoa chowder with sweet potatoes and feta.. what a mix of flavors. I love it!!
If I ever go to NY, we should go running with cocker spaniels. And then eat pie. 🙂
How did you like the leftovers? I love scallions the first time around but whenever they sit in something overnight I get grossed out by the leftovers! So I just always keep ’em separate and throw them on top like garnish.
yum!!! I wouldn’t have thought of using quinoa in chowder! nicely done.
lol! I love reading your posts, they always make me smile! I’m glad you were there to “assist” your roommate and her boyfriend with thier pancakes! I need to check your archives for quinoa recipes… I’m thinking I need to find a few ways to make it so I can add it to my attempt to add more whole grains to my diet.
Glad you save the day with this amazing quinoa chowder! Gotta try 🙂
This sounds lovely, a nice mixture of flavors and a kick with the jalapenos.
I loved hearing this story play out over Twitter, and it’s equally amusing here.
This bowl of food looks so good. I love the colors…just goes to show you how much we eat with our eyes…as a matter of fact I can really taste it just by looking at the pic! 😉
I think you handled that very well, and hate to imagine if you had not been there…plus you got to keep your hand after all, lol :)This is a fantastic soup and worth any delay that may have popped up in the kitchen…love the flavors and combination 🙂
Haha, this was such a fun anecdote to read! And I must say, I am amazed at how beautiful your photos are, given that you had to share a stove to make this dish!
hahaha, you reminded me of the time when my friend and I decided to bake chocolate chip cookies, not realizing that my mom stores chickpea flour in the bin marked “all-purpose” (yeah, her system makes no sense). it was not good.
That looks like what I want to dive into right NOW. Yum!
In some parts of Asia, we would call this congee! I love this idea cos it is one-dish everything healthy and delicious.
This is an absolutely beautiful soup. I LOVE the color the spinach adds to it.
Dear Joanne, What a beautiful and delicious looking soup! Excellent and healthy. Blessings my dear, Catherine xoxo
Dear Joanne, What a beautiful and delicious looking soup! Excellent and healthy. Blessings my dear, Catherine xoxo
Quinoa in soup is very popular in Peru. I think it’s just a lovely choice and the fact that you called it chowder is so fitting. I kept looking for some kind of cream but it’s thick with all the goodness of vegetables. Lovely.
Quinoa chowder! Another Joanne creation I can’t wait to try. Yum.
That’s such a pretty bowl of food 🙂
ouch – we once asked someone just like that to leave our share house – I hope you understand that it just wasn’t on to have my le creuset scratched! some of your stew would have been the comfort we all needed in that house!
This looks AMAZING! Quinoa is so fantastic and I love seeing raw grains and such being used in dishes like these – and with cumin, chili and feta… well, let’s just say you’re speaking my language.
Beautifully simple and healthy. (Although I can’t read “chowder” without hearing Mayor Quimby’s nephew’s voice…) ?
what more can i say other than: thanks for taking all of my favorites and putting them in one dish. love.
Is it bad that we found the pancake more entertaining, just for the comedy value? (ha ha)
Lmao over the metal spatula. I feel the same way every time I find one of my chef knives just laying in the sink with a few dirty dishes. I could scream.
You have to guard the kitchen at all coasts. 😉 Glad you had a chance to make this–it looks fabulous. Such a great combination of ingredients. Thanks for sharing it with Souper Sundays. 😉
maybe that bad pancake motivate you to cook more delicious food in the kitchen. 🙂
This sounds delish! I would have to omit the feta because I am currently off dairy, but the rest? YUM.